

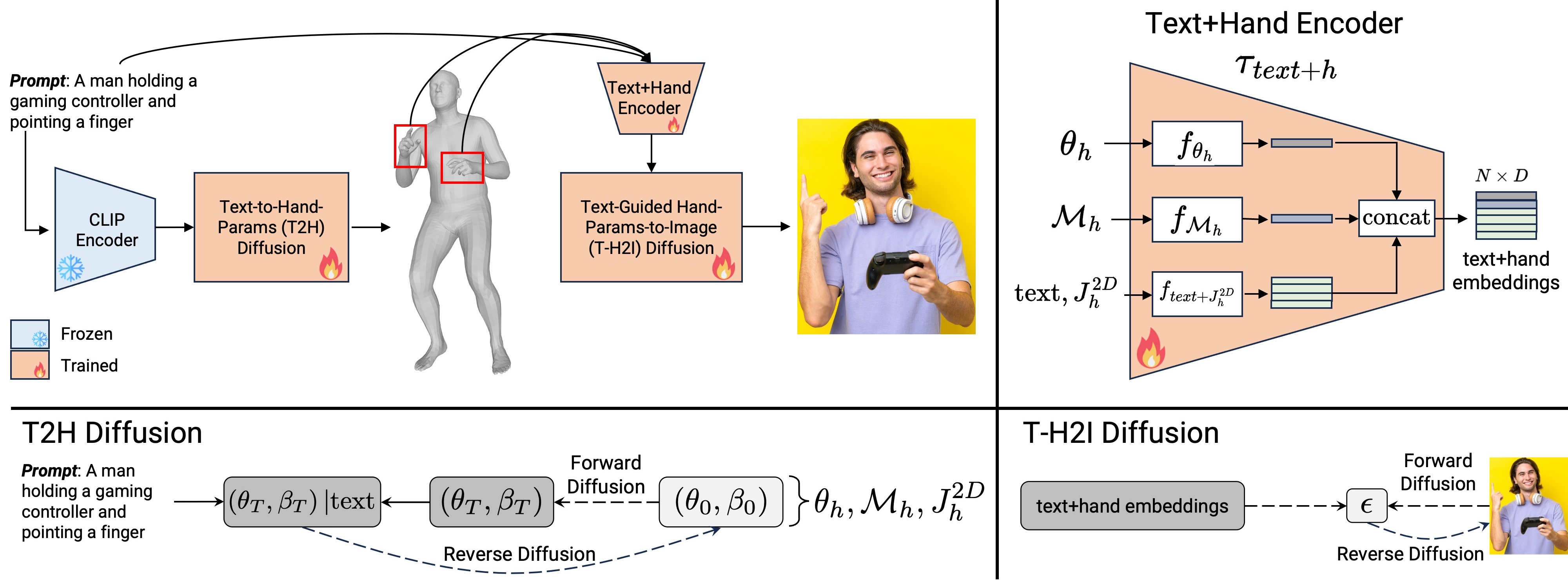
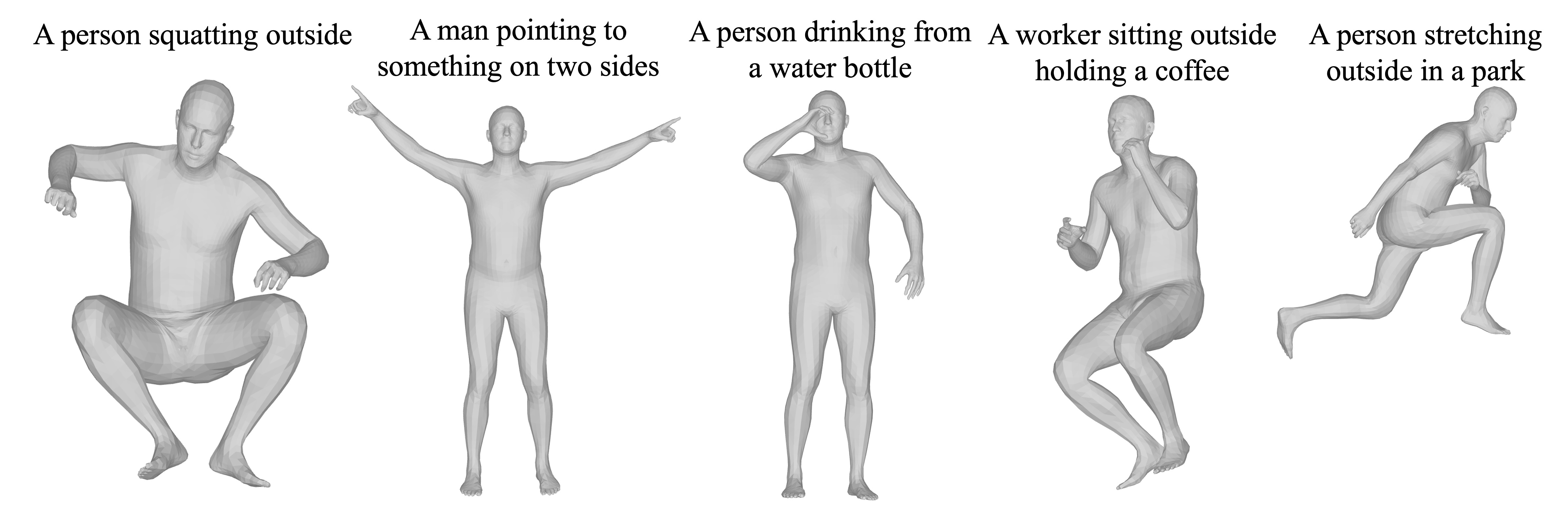
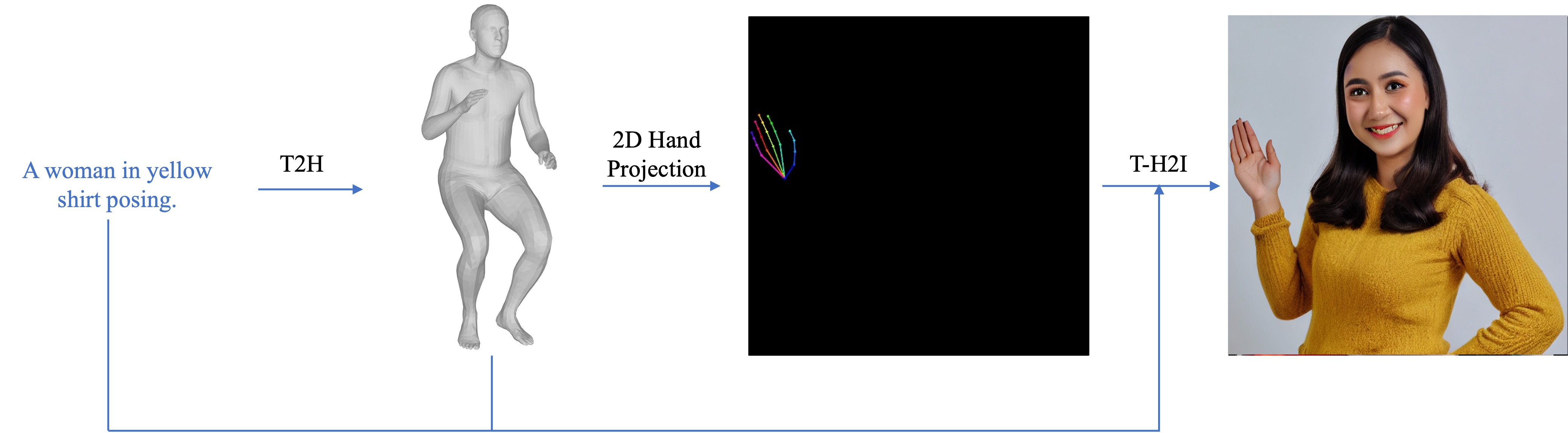
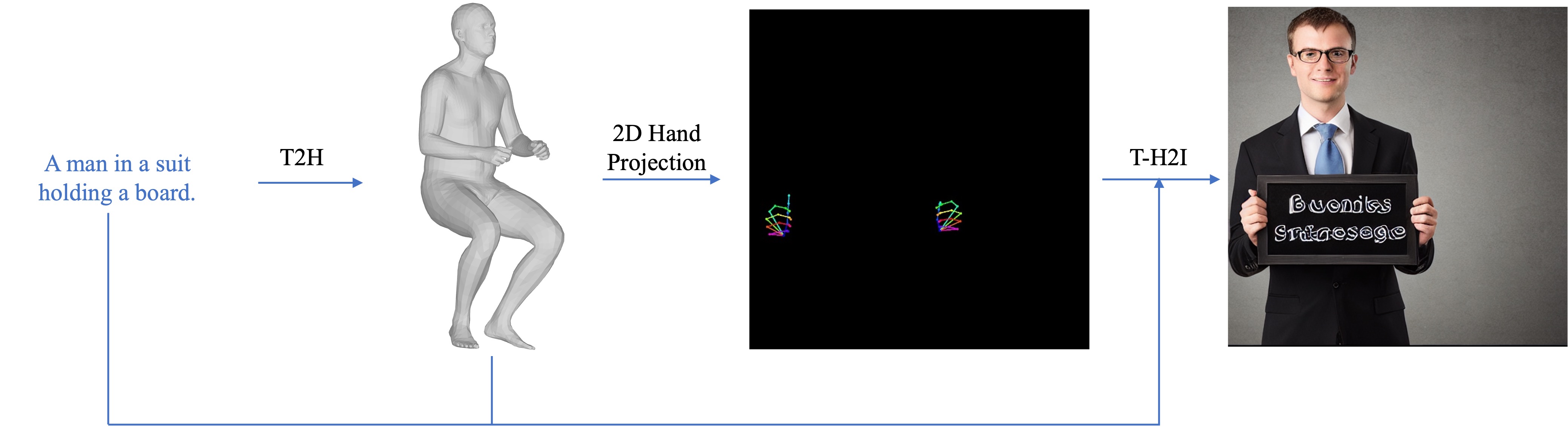
Text-to-image generative models can generate high-quality humans, but realism is lost when generating hands. Common artifacts include irregular hand poses, shapes, incorrect numbers of fingers, and physically implausible finger orientations. To generate images with realistic hands, we propose a novel diffusion-based architecture called HanDiffuser that achieves realism by injecting hand embeddings in the generative process. HanDiffuser consists of two components: a Text-to-Hand-Params diffusion model to generate SMPL-Body and MANO-Hand parameters from input text prompts, and a Text-Guided Hand-Params-to- Image diffusion model to synthesize images by conditioning on the prompts and hand parameters generated by the previous component. We incorporate multiple aspects of hand representation, including 3D shapes and joint-level finger positions, orientations and articulations, for robust learning and reliable performance during inference. We conduct extensive quantitative and qualitative experiments and perform user studies to demonstrate the efficacy of our method in generating images with high-quality hands.








@InProceedings{sn_handiffuser_cvpr_2024,
author = {Supreeth Narasimhaswamy and Uttaran Bhattacharya and Xiang Chen and Ishita Dasgupta and Saayan Mitra and Minh Hoai},
title = {HanDiffuser: Text-to-Image Generation With Realistic Hand Appearances},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
}