


@InProceedings{sn_hoist_cvpr_2024,
author = {Supreeth Narasimhaswamy and Huy Anh Nguyen and Lihan Huang and Minh Hoai},
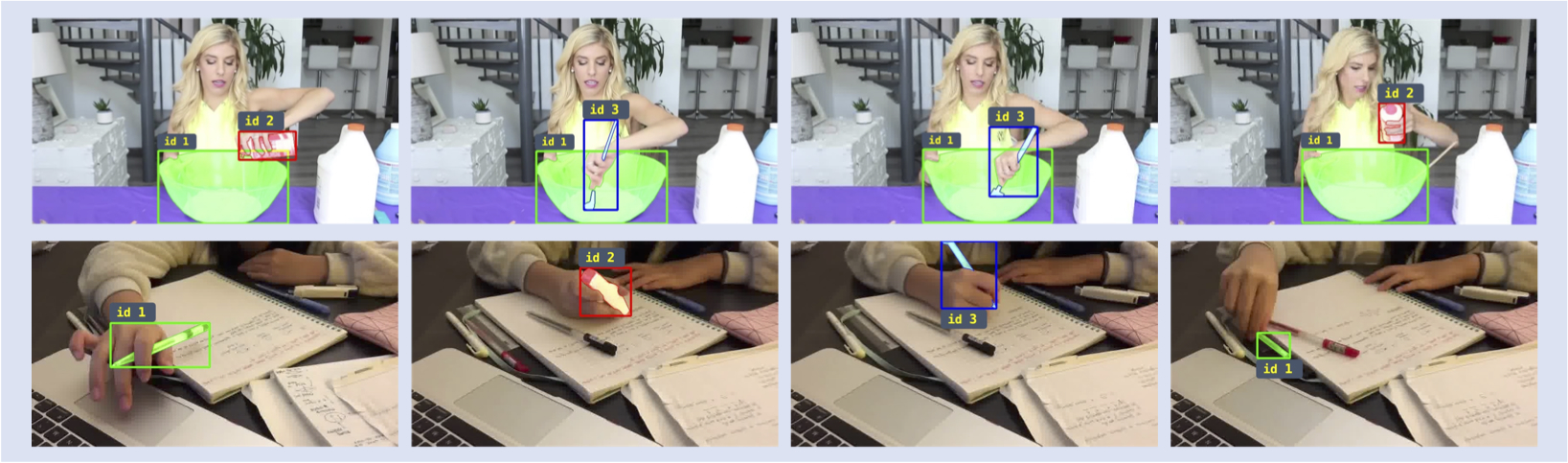
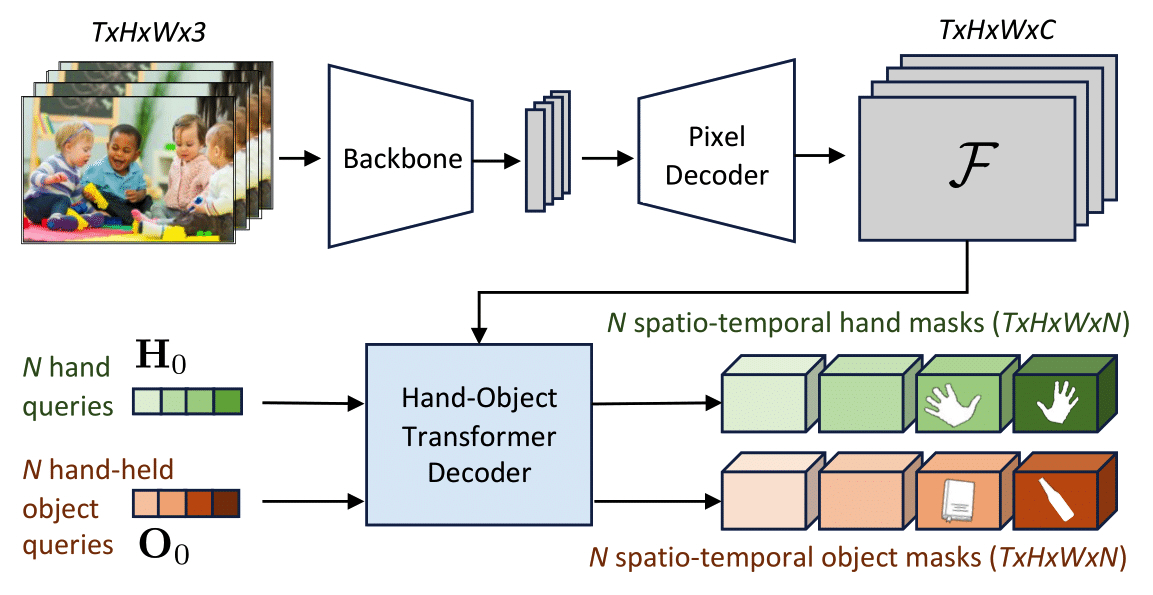
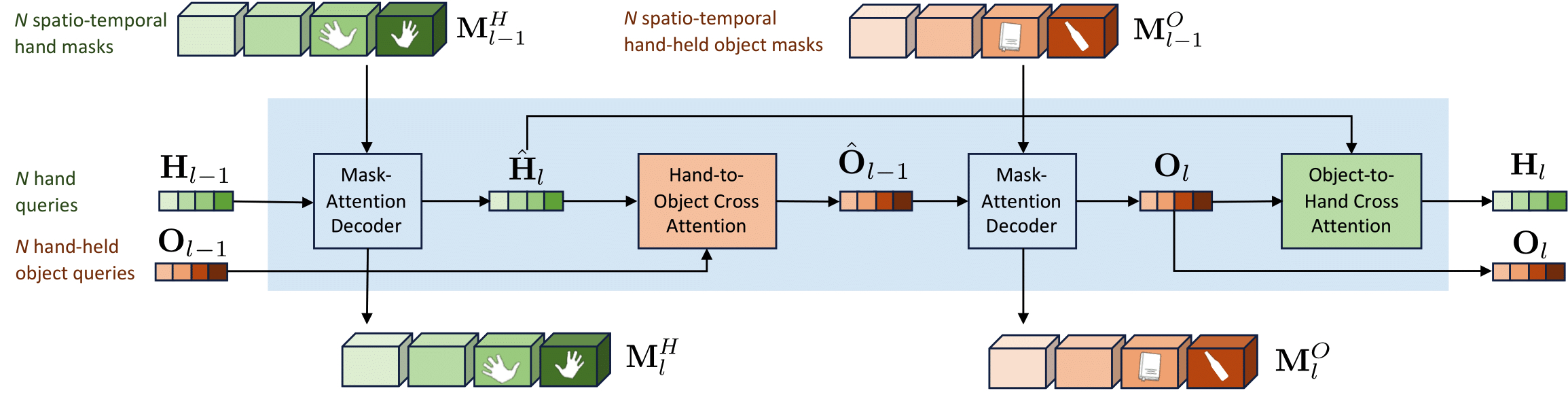
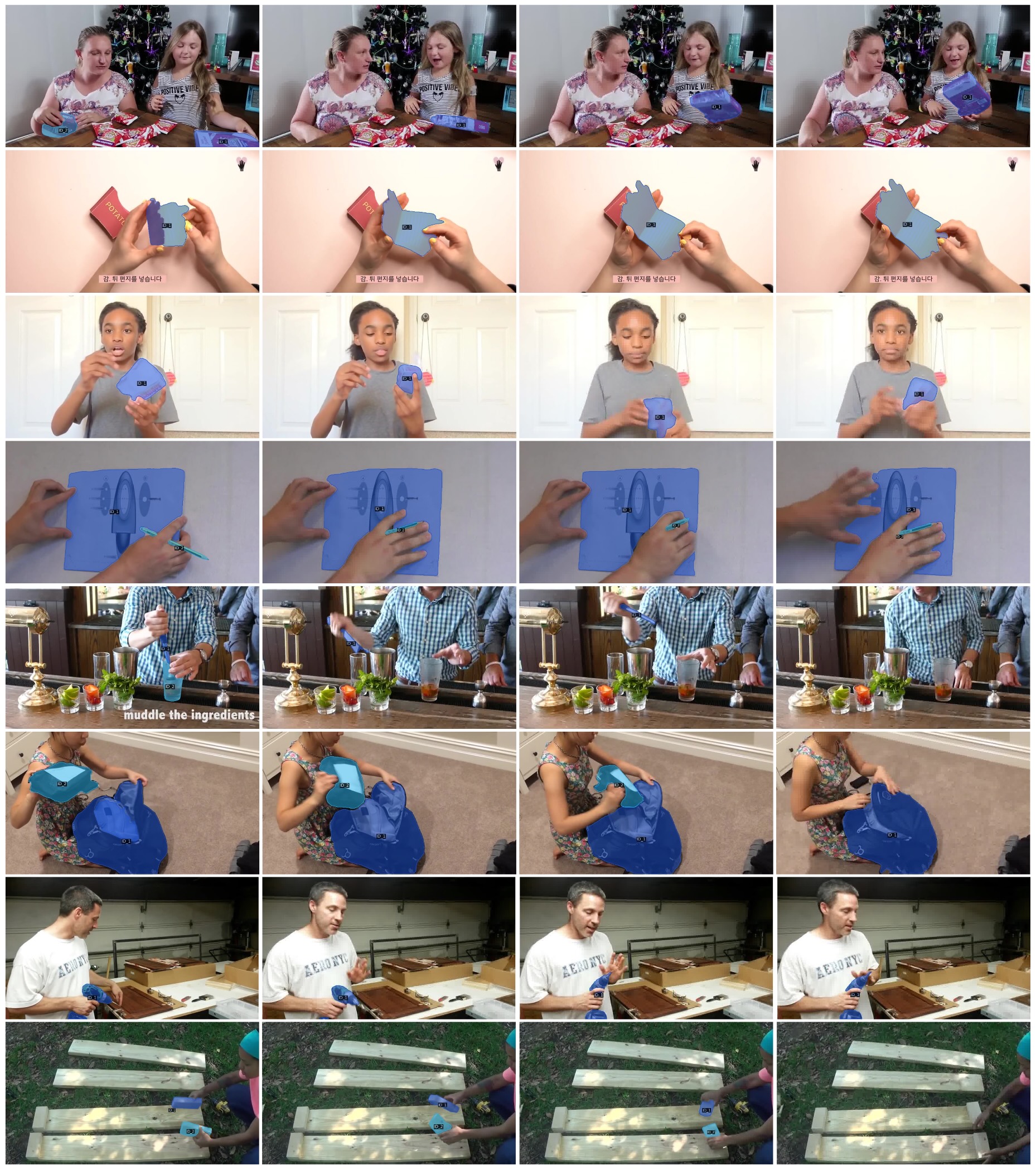
title = {HOIST-Former: Hand-held Objects Identification, Segmentation, and Tracking in the Wild},
booktitle = {IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2024},
}